
There are dozens of PostgreSQL tutorials available in the web which describes the basic PostgreSQL commands. But, when we go in depth with PostgreSQL, we might face a number of practical issues which needs some advanced commands to solve. fbC3yJNdSPwYF34Foce5vA== Such commands or SQL snippet are seldom readily available in PostgreSQL documentation. Here, we are going to discuss a number of PostgreSQL commands which are useful for PostgreSQL developers as well as DBAs.
1. Listing the tables available in database
Some times we may need to get the list tables available in our database. Use the following query to get it:
SELECT table_name FROM information_schema.tables
WHERE table_schema NOT IN ('information_schema','pg_catalog');
The information_schema is a PostgreSQL schema available as per the SQL standards which contains a collection of views such as tables, columns etc. The tables view provides the information about all tables in DB.
The above query will list all the tables from all the schemas of the current DB. But how do we get the tables of some particular schemas ? The following query will do it:
SELECT table_name FROM information_schema.tables
WHERE table_schema NOT IN ('information_schema', 'pg_catalog')
AND table_schema IN('public', 'myschema');
In the last IN clause, we can specify the schema names of our interest.
2. Getting the size of Database
Getting the physical storage size of a database is very helpful in database planning. Use the following command to get the size of a PostgreSQL database in bytes:
SELECT pg_database_size(current_database());
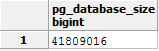
The current_database() is a function which return the name of the database we currently connected to. Also,we can directly give the name of the database:
SELECT pg_database_size('my_database');
Wrapping it inside pg_size_pretty() will give us a human readable format of the same:
select pg_size_pretty(pg_database_size(current_database()));
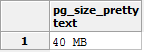
3. Getting the size of a Table
Similarly, we can also get the size of individual tables using pg_relation_size() function:
select pg_relation_size('accounts');
4. Deleting duplicate rows in PostgreSQL
Duplicate rows generally occurs when there is no primary key constraint defined for a table. After staging the table with a huge amount of data and when trying to add constraint we may encounter duplicate rows. There are two kinds of duplications possible:
- The entire row get duplicated several times.
- One or more columns got duplicated(these column(s) are expected to form the PK of the table).
The following ‘customers’ table is one simple example where an entire row (row 2) is get duplicated.
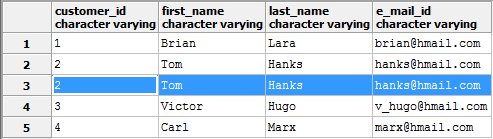
Table having duplicate row in PostgreSQL
In such situations we may use the following query to delete all duplicate rows.
DELETE FROM customers WHERE ctid NOT IN (SELECT max(ctid) FROM customers GROUP BY customers.*) ;
The column ‘ctid’ is a special column available for every tables but not visible unless specifically mentioned. The ctid column value is considered unique for every rows in a table.
Note that the query mentioned here to delete duplicates is a performance intensive query which might run slow for large tables. So care should be taken before doing it in a production environment.
In case if not entire row but only a subset of columns values are repeating, like below:

Table with columns having duplicate values
and if you don’t care about the data and you just want to delete the duplicates, use a query like the following:
DELETE FROM customers WHERE ctid NOT IN (SELECT max(ctid) FROM customers GROUP BY customer_id);
If you do care about the data and want the values to be preserved which otherwise would be deleted, then before deleting the duplicate rows you will have to figure out those rows first:
SELECT * FROM customers WHERE ctid NOT IN (SELECT max(ctid) FROM customers GROUP BY customer_id)

Duplicate rows to be deleted
You can store these rows in some temporary tables or in the same table with some new ‘customer_id’s. After that you can safely delete the duplicates.
Generalized query to delete duplicates: DELETE FROM table_name WHERE ctid NOT IN (SELECT max(ctid) FROM table_name GROUP BY column1, [column 2,] ) ;
5. Safely changing column data type in PostgreSQL
The PostgreSQL commands to alter a column’s data type is very simple. Now you might be thinking, why I included it in the list of useful PostgreSQL Commands. Fine, let’s go through such an example of changing data type of a column of our ‘customers’ table we discussed just before. You can see from the above image that I have used the data type – ‘character varying’ for ‘customer_id’ column. But it was a mistake, because I am always giving integers as customer_id. So using varchar here is a bad practice. So let’s try to change the column type to integer –
ALTER TABLE customers ALTER COLUMN customer_id TYPE integer;
But it returns:
ERROR: column “customer_id” cannot be cast automatically to type integer
SQL state: 42804
Hint: Specify a USING expression to perform the conversion.
That means we can’t simply change the data type because data is already there in the column. Since the data is of type ‘character varying’ postgres cant expect it as integer though we entered integers only. So now, as postgres suggested we can use the ‘USING’ expression to cast our data into integers.
ALTER TABLE customers ALTER COLUMN customer_id TYPE integer USING (customer_id::integer);
It works!
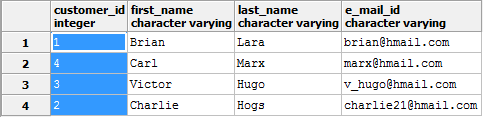 Also remember, the USING expression is not limited to ‘casting’. It can include expressions having functions, other columns of the tables and operations.
Also remember, the USING expression is not limited to ‘casting’. It can include expressions having functions, other columns of the tables and operations.
For example we can change back the customer_id column in to ‘character varying’ with a different ID format using:
ALTER TABLE customers ALTER COLUMN customer_id TYPE varchar USING (customer_id || '-' || first_name);
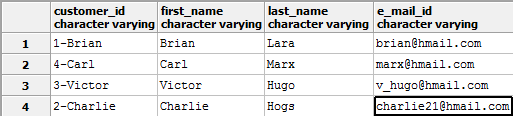
Customer table with changed data type
6. Know who is connected to the Database
This is more or less a monitoring command. To know which user connected to which database including their IP and Port use the following SQL:
SELECT datname,usename,client_addr,client_port FROM pg_stat_activity ;
7. To know whether a User is Connected or Not
SELECT datname FROM pg_stat_activity WHERE usename = 'devuser';
If this query returns at least one row, we can make sure that the user is connected to the database.
8. Reloading PostgreSQL Configuration files without Restarting Server
PostgreSQL configuration parameters are located in special files like postgresql.conf and pg_hba.conf. Often, you may need to change these parameters. But for some parameters to take effect we often need to reload the configuration file. Of course, restarting server will do it. But in a production environment it is not preferred to restarting the database, which is being used by thousands, just for setting some parameters. In such situations, we can reload the configuration files without restarting the server by using the following function:
select pg_reload_conf();
Remember, this wont work for all the parameters, some parameter changes need a full restart of the server to be take in effect.
9. Getting the data directory path of the current Database cluster
It is possible that in a system, multiple instances(cluster) of PostgreSQL is set up, generally, in different ports or so. In such cases, finding which directory(physical storage directory) is used by which instance is a hectic task. In such cases, we can use the following command in any database in the cluster of our interest to get the directory path:
SHOW data_directory;
The same function can be used to change the data directory of the cluster, but it requires a server restarts:
SET data_directory to new_directory_path;
10. Finding missing values in a Sequence
Often we use sequences in our tables as primary keys, as we used integers in our customers table. But some times it is possible that some values will be missing or deleted which actually can be used again. But for large tables it is difficult to find these missing values.
 Method 1
Method 1
So, in such cases we can use the following query to find the starting of such missing value intervals.
SELECT customer_id + 1
FROM customers mo
WHERE NOT EXISTS
(
SELECT NULL
FROM customers mi
WHERE mi.customer_id = mo.customer_id + 1
)
ORDER BY customer_id
Output:
 Otherwise if you want to get not just the starting value but all the values that are missing use this query(performance intensive!):
Otherwise if you want to get not just the starting value but all the values that are missing use this query(performance intensive!):
WITH seq_max AS ( SELECT max(customer_id) FROM customers ), seq_min AS ( SELECT min(customer_id) FROM customers ) SELECT * FROM generate_series((SELECT min FROM seq_min),(SELECT max FROM seq_max)) EXCEPT SELECT customer_id FROM customers
Output:
 Method 2 (By Bartek)
Method 2 (By Bartek)
1. get the name of the seq. associated with customer_id:
SELECT pg_get_serial_sequence('customers', 'customer_id')
2. find all missing IDs:
WITH sequence_info AS ( SELECT start_value, last_value FROM "SchemaName"."SequenceName" ) SELECT generate_series ((sequence_info.start_value), (sequence_info.last_value)) FROM sequence_info EXCEPT SELECT customer_id FROM customers
Keep in touch to get more useful PostgreSQL Commands!
So, we have seen the 10 PostgreSQL commands, which solves some of the most common problems faced by most of the PostgreSQL developers or Admins. But this is not the end! There are hundreds of PostgreSQL commands out there which come handy in several situations. Be in touch with technobytz to get more such commands!
10 comments
Hi,
First of all: thanks for explanation
I’ve got a comment for #10:
Your example doesn’t care about start and current value of sequence. What if first n rows has been deleted so there are no 1,2,…n values existing in table?
Same question for last values…
My suggestion is to use sequence params (start_value and last_value), eg:
1. get the name of the seq. assosiated with customer_id
SELECT pg_get_serial_sequence('customers', 'customer_id')2. find all missing IDs:
WITH sequence_info AS (
SELECT start_value, last_value FROM "SchemaName"."SequenceName"
)
SELECT generate_series ((sequence_info.start_value), (sequence_info.last_value))
FROM sequence_info
EXCEPT
SELECT customer_id FROM customers
Output could be a little bit different 🙂
Regards,
Bartek
Awesome! I will add this method also.
Hi,
my suggestion for your ‘performance intensive’ query in “10. Finding missing values in a Sequence” is the following:
SELECT * FROM generate_series(1,(SELECT max(customer_id) + 1 FROM customer)) AS res_no
EXCEPT
SELECT customer_id FROM customer order by res_no;
this way it finds all missing IDs including those start before the min(customer_id), and the first available(max(customer_id) + 1).
Regards,
Danilo
It is in reality a great and helpful piece of information.
I am happy that you simply shared this helpful info with us.
Please keep us informed like this. Thanks for sharing.
Excellent Article 🙂
Thank you for all this information.
Happy to know that there is people like you in this world ^^.
🙂
[…] From http://technobytz.com/most-useful-postgresql-commands.html […]
Nice informative blog post. Thanks.
Sir good morning, I had go through above all commands , its very useful . I need a help how to alter columns datatype without deleting views dependent in that. Is there any options for recompile views automatically