
In this post we will discuss about the usage of GROUP BY clause and Aggregate Functions in PostgreSQL. PostgreSQL is having a large number of useful aggregate functions. We will see a few of the most important functions, skipping the common ones like sum(), avg() etc.
Consider the following table:
CREATE TABLE products ( id integer NOT NULL, name character varying, cost double precision, manufacturer character varying, warranty character varying, category character varying, in_stock boolean, CONSTRAINT products_pkey PRIMARY KEY (id) )
Quick Navigation
1. General Form of GROUP BY Clause
Assume that we want to get the total number of Bags and Men’s Clothing from the product table. We write a query like this:
SELECT category, count(1) FROM products GROUP BY category;
 Things to remember:
Things to remember:
- The SELECT part should not contain any columns not referenced in GROUP BY clause, unless it is wrapped with an aggregate function.
So, the following query is wrong:SELECT name, count(1) FROM products GROUP BY category;
And will return the error: “column “products.name” must appear in the GROUP BY clause or be used in an aggregate function”
But, this query is perfectly fine:SELECT string_agg(name, ', '), count(1) FROM products GROUP BY category;

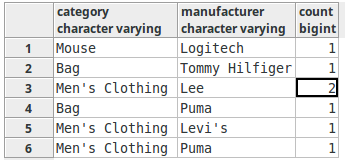
- Multiple columns can be included in the GROUP BY clause, separated by commas. In this case, the grouping is done based on each unique combination of the values in the columns, in the given order. Example:
SELECT category, manufacturer, count(1) FROM products GROUP BY category, manufacturer;
2. GROUP BY with HAVING
This time, I have a slightly different requirement:
Return the product category and count as before, but exclude the categories whose count of product is one.
SELECT category, count(1) FROM products GROUP BY category HAVING count(name) != 1;
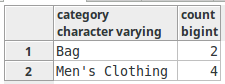
So, apparently, the condition in the HAVING clause is applied to each group, individually. It is the GROUP BYs counterpart of “WHERE” clause.
Note that, as in the case of SELECT clause, the HAVING clause should not contain any column that is not used in the GROUP BY clause, unless it is inside an Aggregate Function.
3. string_agg() function
We have already seen a query with string_agg() function.
SELECT string_agg(name, ' | '), count(1) FROM products GROUP BY category;

The second parameter of the string_agg() is the delimiter, as evident from the result.
Note that all aggregate functions will also work in normal queries without a GROUP BY clause. The only difference when used without GROUP BY is that the function is applied to the whole rows.
4. bool_and() function
Bool and function is a particularly useful function in a number of situations.
Suppose that we want to get the list of categories in which at least on product is out of stock.
SELECT category FROM products GROUP BY category HAVING bool_and(in_stock) IS TRUE;

As evident from the query result, bool_and() return a TRUE when all of its parameters(cells) are TRUE. In other words it performs a logical AND between all the parameters.
Note that the bool_and() excludes any NULL values, that is why the “Bag” is listed in the result.
bool_or() is the OR counterpart of bool_and, which return true if at least one of the parameter is TRUE.
There are lots of other aggregate functions available in PostgreSQL.
For a complete list, refer the PostgreSQL documentation.
PostgreSQL supports creation of user defined aggregate functions using the command: CREATE AGGREGATE…